
Terwijl er nog bedrijven zijn die denken waarde te kunnen halen uit hun eigen datacenters, oriënteert een toenemend aantal zich op de cloud waaraan zij zowel de primaire als secondaire applicaties willen toevertrouwen. In hun zoektocht naar mogelijkheden om de verschillende datastromen binnen hun organisaties sneller te gelde te maken, komen ze terecht bij zowel public cloud- als private cloud-aanbieders. De CIO die cloud native hoog in het vaandel heeft staan, kan bedrogen uitkomen met de complexe materie rond het beheer van multicloud-architecturen. Open source Kubernetes-technologie biedt uitkomst.
De selectie van de cloud-dienst geschiedt vaak op basis van criteria als lagere exploitatiekosten en de hogere uitrolsnelheid van applicaties. Maar omdat veel ondernemingen in eigen beheer IT-systemen hebben opgetuigd waarmee men zich kan onderscheiden van de concurrentie of die van grote waarde zijn voor de primaire processen, blijven de on-premise toepassingen en onderliggende infrastructuur gehandhaafd.
Vervolgens gaan we data uit de drie domeinen met elkaar verbinden, zodat er weer nieuwe vormen van data ontstaan. Dataopslag wordt data-assemblage en van datacenters gaan we naar data-fabricage. En al dat data-kapitaal moet ter beschikking staan van alle applicaties, ongeacht de infrastructuur waarin ze zijn ondergebracht.
CIO’s willen snel kunnen schakelen tussen de verschillende omgevingen zonder migratieproblemen met de data en zonder dat door een hoge werklast op de verschillende platformen de hardware-kosten de pan uitrijzen. Die werklast zal in toenemende mate komen in de vorm van containers. Software en data verpakt in autonoom gebouwde en onderhouden microservices genieten grote belangstelling binnen bedrijven waar de DevOps-principes zich bewijzen rondom het geïntegreerd ontwikkelen, testen en in productie nemen van applicaties.
Containers op alle infrastructuur
In de containers treffen we applicaties aan die slechts op één of enkele processen kunnen draaien. Containers bieden ontwikkelaars snelheid, flexibiliteit en keuzemogelijkheden. Daarnaast zijn containers niet eenkennig als het gaat om de onderliggende infrastructuur. Ze werken op servers in de cloud of on-premise, maar dezelfde containers laten zich ook toepassen op desktops en laptops. Daar waar ze nodig zijn, laten ze zich snel installeren en opschalen. In de ontwikkelomgeving, de testomgeving, de acceptatie-omgeving en de productie-omgeving.
Dankzij het denkwerk van specialisten bij Google beschikken we inmiddels over open source-technologie om het aanmaken, het beheren en het onderlinge afstemmen van containers te managen. Zij noemden hun geesteskind Kubernetes, afgeleid van het Griekse woord voor stuurman.
Zo’n geautomatiseerde ‘roerganger’ blijkt nuttig nu we in de cloud de grenzen van de virtualisatietechnologie naderen. Bij computerinstallaties passen we al heel lang gevirtualiseerde verwerkingsprincipes toe met Virtual Machines (VM), waardoor we een groot aantal applicaties, inclusief databestanden voor een groot aantal gebruikers gelijktijdig op één fysiek computersysteem laten draaien.
In theorie maakt het clusteren van fysieke systemen in een datacenter de virtuele verwerkingsomgevingen nog veel krachtiger. In de praktijk blijkt dat de overhead die wordt veroorzaakt doordat alle onderdelen van de besturingssoftware in de VM-omgeving meervoudig zijn geladen, een groot beslag kan leggen op de rekenkracht van de fysiek aanwezige CPU’s. De prestaties nemen dus niet exponentieel toe naarmate we de processorcapaciteit opschalen. Bij het opsplitsen van applicaties in een reeks van containers speelt overhead geen rol vanwege de losse binding met het besturingssysteem, terwijl elke container wel is voorzien van een eigen bestandsstructuur, CPU-capaciteit en data-opslag.
Last van legacy en virtuele overhead
Kubernetes-technologie existeerde een tijdje naast de VM-technologie op veel servers in cloud- en on-premise datacenters. Aan die vreedzame co-existentie lijkt een einde te komen door de Kubernetes-inspanningen van het bedrijf Diamanti uit het Californische San Jose. Hun klanten, die cloud-native applicaties implementeren, realiseren zich dat ze moeten jongleren met een verzameling deeloplossingen om hun data in samenhang met de applicaties te beheren. De aanwezige besturingssystemen leveren te weinig inzicht op. De op de markt verkrijgbare legacy-oplossingen bieden nauwelijks soelaas. Ze hebben veel last van virtualisatie-overhead. Terwijl eindklanten profiteren van een overvloed aan functies, geboden door public en private-clouds, zien de applicatiebeheerders zich geconfronteerd met de complexiteit in de omgang met inconsistenties.
Met Diamanti Spektra leveren de Californiërs een holistisch platform met een geïntegreerde controle over data en processen in de containers vanaf de I/O‑operatie van een enkelvoudige container tot aan meervoudige clusters in hybride omgevingen. Op deze manier zijn applicaties en data op elk moment met minimale impact te migreren. Het platform functioneert als een compleet op maat geleverde hybride cloud-oplossing waarmee afnemers onmiddellijk aan de slag kunnen. Kubernetes ’on bare metal’ voorziet in orkestratiefunctionaliteit van containers rechtstreeks op de onderste laag (Linux) zonder de overhead van Virtual Machines. Daarmee laten Kubernetes-clusters op uiteenlopende infrastructuren zich probleemloos verplaatsen tussen public clouds, private clouds en on-premise omgevingen. IT-managers kunnen de meest geschikte infrastructuur selecteren voor hun applicaties op basis van uiteenlopende criteria. Denk aan kosten, beschikbaarheid, het beleid rond databeheer, toegang tot specifieke functies en de herstelmogelijkheden na incidenten.
Kubernetes appliance
Naast het softwareplatform Spektra levert Diamanti ook hardware in de vorm van de D20 appliance. Deze is gebaseerd op standaard Intel Xeon-processoren. Daarmee laat zich binnen een kwartier een volledige container stack uitrollen op basis van de open souce-oplossingen Kubernetes 1.12 of Docker 1.13.
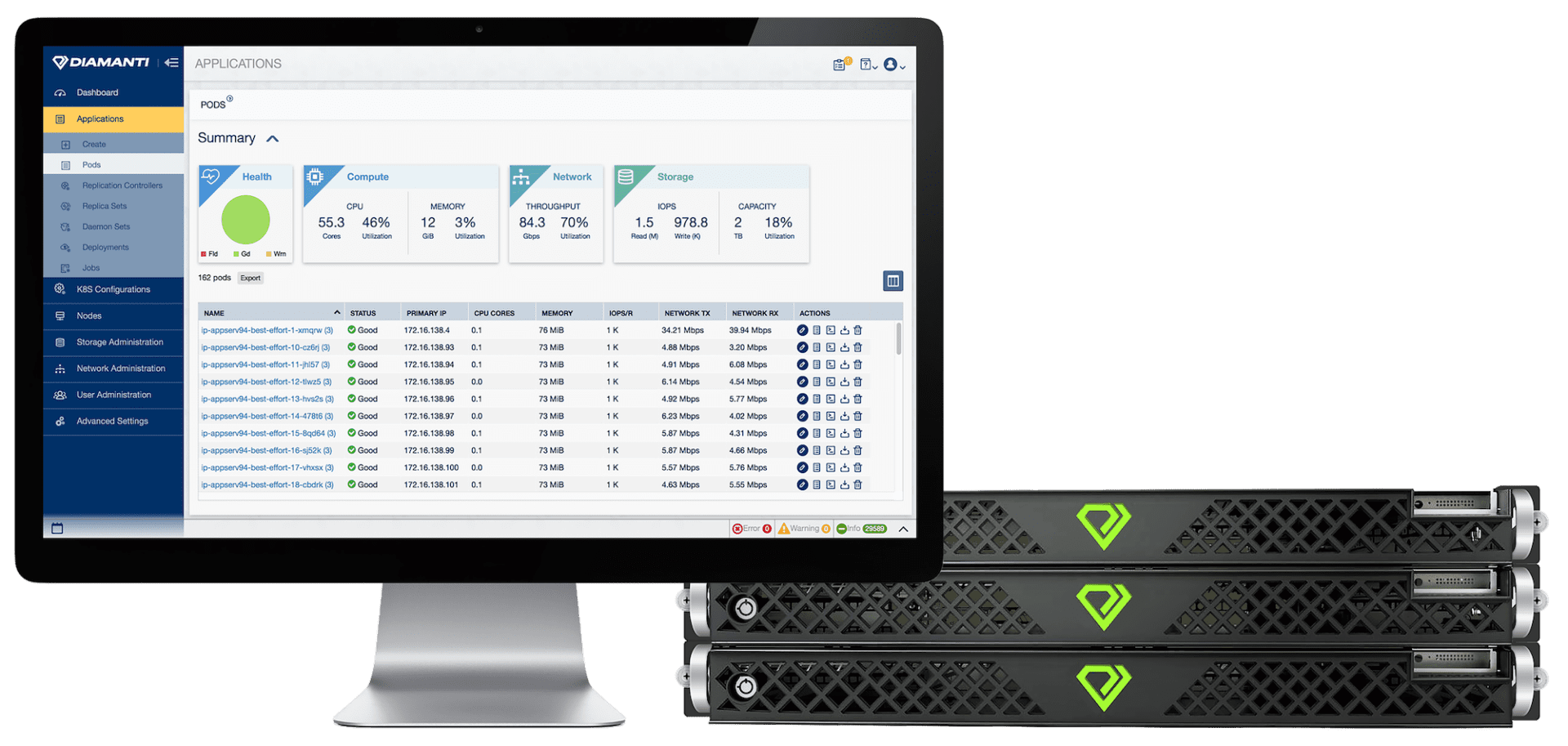
De appliance bewijst zich volop in omgevingen met intensieve I/O afhandeling, waar te zware CPU-belasting en de overhead van virtualisatie de prestaties dreigen te beïnvloeden. Denk aan toepassingen als AI, machine learning, bij 5G/Edge-toepassingen en bij het draaien van applicaties als Elastic, Splunk en Kafka.
Frans van der Geest is journalist
