Een internetstoring kan voor elk bedrijf enorme gevolgen hebben. Doordat gebruikers bij een storing geen toegang hebben tot applicaties en diensten, is de kans op een forse omzetdaling en omvangrijke reputatieschade groot. Daarbij is het leveren van applicaties niet alleen afhankelijk van veel verschillende Internet Service Providers (ISP’s), maar in toenemende mate ook van een groot en complex ecosysteem van internetdiensten, zoals CDN, DNS, DDoS-bescherming en public cloud. Deze diensten werken samen aan het leveren van optimale gebruikerservaringen en zelfs korte onderbrekingen kunnen al serieuze gevolgen hebben.
Een internetstoring kan voor elk bedrijf enorme gevolgen hebben. Doordat gebruikers bij een storing geen toegang hebben tot applicaties en diensten, is de kans op een forse omzetdaling en omvangrijke reputatieschade groot. Daarbij is het leveren van applicaties niet alleen afhankelijk van veel verschillende Internet Service Providers (ISP’s), maar in toenemende mate ook van een groot en complex ecosysteem van internetdiensten, zoals CDN, DNS, DDoS-bescherming en public cloud. Deze diensten werken samen aan het leveren van optimale gebruikerservaringen en zelfs korte onderbrekingen kunnen al serieuze gevolgen hebben.
Tegelijkertijd vertrouwen bedrijven steeds meer op het internet om hun locaties onderling te verbinden en kritische applicaties en diensten beschikbaar te stellen. Applicaties worden steeds vaker niet meer in eigen datacenters gehost en vestigingen zijn al lang niet meer onderling verbonden via MPLS. Het internet doet dienst als vervanging voor of aanvulling op MPLS nu bedrijven steeds vaker kiezen voor SD-WAN-technologieën. Zo is het internet nu feitelijk de backbone van een onderneming. Maar dit ´best effort´-transport kan behoorlijke (onvoorziene) consequenties hebben.
Wij hebben in het afgelopen jaar verschillende grootschalige internetstoringen gerapporteerd. De storingen met de meeste impact vonden plaats in de zomer van 2019 en raakten nagenoeg elk groot techbedrijf.
Dit waren in chronologische volgorde de grootste storingen van 2019 en de lessen die ze ons leren.
13 mei 2019 — De storing bij China Telecom laat de wereldwijde reikwijdte van het bedrijf zien
Dit was weliswaar niet de grootste storing van 2019, maar wel een wereldwijde en redelijk langdurige. Het zorgde voor verschillende incidenten en illustreerde de reikwijdte van China Telecom, die veel verder gaat dan China.
Op 13 mei was er gedurende vijf uur sprake van substantieel packet loss binnen de backbone van China Telecom. Dat had met name impact op de netwerkinfrastructuur in China zelf, maar ook op het netwerk in Singapore en op verschillende punten in de Verenigde Staten, waaronder Los Angeles. Meer dan honderd diensten hadden last van de storing. Hoewel de storing geen exclusieve impact had op diensten in het westen, moeten veel gebruikers van grote westerse techbedrijven als Apple, Amazon, Microsoft, Slack, Workday en SAP er last van hebben gehad.
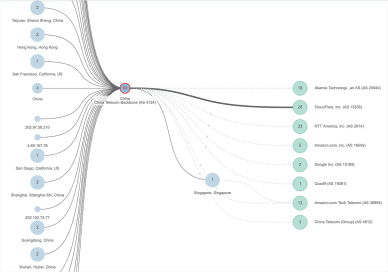
Figuur 1: clouddiensten die getroffen werden door de storing bij China Telecom
Dit incident laat zien dat China een grotere invloed heeft op het wereldwijde internet dan velen tot nu toe dachten. Meer specifiek illustreert het incident dat de censuur van China verdergaat dan eigen landgrenzen en zich uitstrekt tot landen waar een heel ander beleid voor internetgebruik geldt.
2 juni 2019 — De ‘zomer van de storingen’ begint met Google Cloud
Op 2 juni was er bij het Google Cloud Platform (GCP) sprake van een flinke netwerkstoring die van invloed was op diensten in het oosten, midden en westen van de Verenigde Staten. De storing was van invloed op de eigen applicaties van Google, waaronder GSuite en YouTube, en duurde meer dan vier uur – wat lang is, gezien de kritische aard van de diensten voor zakelijke gebruikers. Google bracht enkele dagen later een officieel rapport uit over het incident. ThousandEyes zag met behulp van zijn vantage points in realtime hoe de storing zich ontwikkelde en kon al ‑voordat er meer detailinformatie bekend was- de kenmerken en de schaalgrootte van de storing aangeven.
Deze begon rond 9.00 uur lokale tijd in het oosten van de Verenigde Staten. ThousandEyes constateerde honderd procent packetloss van wereldwijde monitors die probeerden een verbinding te maken met een service die gehost werd in GCP us-west2‑a. Hetzelfde verlies zagen we bij sites die gehost werden in delen van GCP us-east, waaronder us-east4‑c.
Figuur 2: gebruikers kunnen een service die gehost wordt in GCP us-west, niet bereiken
De volledige onbereikbaarheid van delen van Google’s netwerk was – zo constateerde ThousandEyes – te wijten aan het per ongeluk offline halen van een netwerk-control plane. Google meldde later dat gedurende de storing een set van automatische policy’s bepaalde welke services wel en welke niet bereikbaar waren via de niet-getroffen delen van zijn netwerk.
Een van de belangrijkste lessen van een dergelijke cloudstoring is de duidelijke noodzaak van een cloudarchitectuur met voldoende betrouwbaarheidsmaatregelen, zij het op een multiregio- of multicloudbasis. Het ligt immers voor de hand dat technologie soms last zal hebben van een storing.
6 juni 2019 — Een ongelukkige samenloop van omstandigheden maakt WhatsApp onbereikbaar voor veel gebruikers
Op 6 juni hadden veel WhatsApp-gebruikers wereldwijd last van connectiviteitsissues. ThousandEyes zag direct dat honderd procent packetloss ervoor zorgde dat de service niet bereikbaar was. Na een nadere analyse zagen we dat de oorzaak lag in een omvangrijke route leak die verkeer leidde naar China Telecom. Deze serviceprovider stuurt echter geen Facebook-verkeer door.
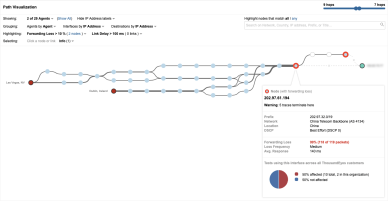
Figuur 3: China Telecom stuurt WhatsApp-verkeer niet door
Klinkt ingewikkeld? Hieronder de feiten op een rij.
Het incident ontstond toen het Zwitserse colocatiebedrijf Safe Host aan het internet liet weten dat WhatsApp en duizenden IP-prefixes het beste te bereiken zouden zijn via zijn AS 21217-netwerk. Toen Safe Host deze routes bekendmaakte, werden ze geaccepteerd door China Telecom en verder verspreid via andere ISP’s, waaronder Cogent. Gebruikers van wie het verkeer naar Cogent werd gerouteerd – en dat uiteindelijk bij China Telecom terechtkwam –, konden de service niet meer bereiken.
Het is niet duidelijk waarom China Telecom routes accepteerde naar een dienst die het censureert. De les van deze storing is wel duidelijk: BGP route leaks zijn niet ongewoon op het internet. Wanneer je op het internet vertrouwt, dan is het zaak dat je weet hoe het werkt en dat een kleine storing bij een serviceprovider gevolgen kan hebben voor andere partijen. Het is helaas de realiteit dat de risico’s van BGP route leaks en andere internettekortkomingen voor bedrijven toenemen, gezien het moderne service delivery-landschap.
24 juni 2019 – Gebruikers van Cloudflare zijn het slachtoffer van een routingfout
Slechts enkele weken na de grote WhatsApp-storingen was er opnieuw sprake van een routegerelateerd incident. En dit keer was de schade groter.
Op 24 juni zorgde een flinke BGP-routingfout twee uur lang voor problemen met de toegang tot de services via de CDN-leverancier Cloudflare, waaronder de gamingplatforms Discord en Nintendo Life. Een analyse van ThousandEyes liet zien dat een significante BGP route leak verschillende prefixes van verschillende providers had aangetast. DQE, een transitprovider, was de originele bron van de route leak, die was verspreid via Allegheny Technologies, een klant van zowel DQE als Verizon. Ongelukkigerwijze verspreidde Verizon de route leak verder, waardoor het effect werd versterkt.
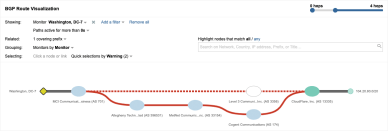
Figuur 4: een opvallende path change voor toegang tot een Cloudflare-gerouteerde prefix
Sites die via het Cloudflare CDN geserveerd worden, hadden twee uur last van de storing die rond de vijftien procent van het wereldwijde Cloudfare-verkeer en ‑services als Discord, Facebook en Reddit beïnvloedde. De route leak had ook invloed op toegang tot sommige AWS-services.
De kernoorzaak van het incident bleek het gebruik van BGP-optimalisatiesoftware door DQE. Deze software creëerde routes naar Cloudflare-services, die alleen bedoeld waren voor gebruik binnen het interne netwerk van DQE. Nu deze routes per ongeluk naar een van zijn klanten werden gelekt, ging het mis.
Dit incident laat opnieuw zien hoe makkelijk het is om een wijziging aan te brengen in het internetlandschap. Bedrijven hebben daarom inzicht nodig in het internet om vandaag de dag succesvol diensten aan gebruikers te kunnen leveren.
6 september 2019 — DDoS-aanvallers belagen Wikipedia
Op 6 september waren Wikipedia-sites overal in de wereld gedurende bijna negen uur niet bereikbaar door een grootschalige en hardnekkige Distributed Denial of Service-aanval (DDoS). DDoS-aanvallen kunnen de webomgeving van een doelwit volledig overspoelen met data en tevens zorgen voor filevorming binnen serviceprovidernetwerken. Dat kan weer leiden tot packetloss. Dit was precies wat ThousandEyes zag gebeuren bij deze aanval op Wikipedia.
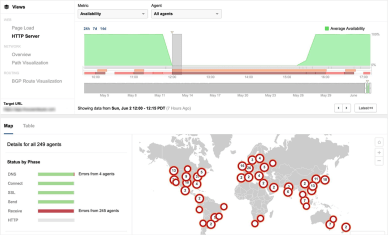
Tijdens dit incident zagen we een significante terugval in de beschikbaarheid van http-servers overal in de wereld en een sterke verslechtering van de http-responstijden. Daardoor was het voor veel mensen in tal van regio’s niet mogelijk om via internet contact te leggen met Wikipedia-servers. ThousandEyes constateerde ook packetloss tot wel zestig procent, wat tevens bijdroeg aan de onbereikbaarheid van Wikipedia-sites.

Figuur 5: de http-responstijden namen tijdens de aanval wereldwijd sterk toe
DDoS-aanvallen gebeuren helaas op het internet, echter de getroffen organisatie dient dan wel inzicht te hebben in de scope, de impact en het gedrag van een aanval, zodat zij kan bepalen of de stappen die tegen een aanval genomen worden, echt effectief zijn.
Het internet is voor veel bedrijven een black box, Wanneer er een storing optreedt, kunnen IT- en operationele teams de oorzaak vaak moeilijk bepalen en is een effectieve reactie lastig. Aangezien het internet veel afhankelijkheden kent en fragiel van aard is, zijn storingen onvermijdelijk. Echter, inzicht in deze storingen kan de tijd die nodig is voor escalatie en het oplossen van problemen, sterk verkorten. Ook is dan beter met klanten te communiceren.
Wie de risico’s van het onvoorspelbare internet wilt beheersen, wordt het tijd om de mogelijkheden van ThousandEyes te onderzoeken. Wij lanceerden onlangs Internet Insights, een dienst die de collectieve gegevens van miljoenen dagelijkse internetmetingen bij elkaar brengt en een totaalbeeld creëert van de actuele gezondheid van het internet.
Internet Insights identificeert en isoleert storingen bij specifieke serviceproviders en op specifieke locaties. De storingen worden op een in NOC-stijl vormgegeven dashboard gepresenteerd via views met tijdlijnen en topografische data. Deze door data gedreven inzichten helpen Operations-teams bij de storingsafhandeling van incidenten en netwerkmanagers en planners bij het creëren van inzicht in de betrouwbaarheid van providers.

