
Om klanten te helpen generatieve AI te gebruiken met eigen data en bedrijfscontext, inclusief beveiliging en governance, heeft Cloudera de volgende samenwerkingen rond generatieve AI aangekondigd: met vectordatabaseleverancier Pinecone, fabrikant van AI-chips NVIDIA en AWS Bedrock, een nieuwe toolset voor het bouwen van generatieve AI op AWS.
Pinecone AI-vectordatabase
Cloudera gaat met Pinecone samenwerken om de AI-vectordatabase-expertise van het bedrijf te integreren in Cloudera’s open dataplatform. Met als doel het transformeren van de manier waarop organisaties de kracht van AI benutten om processen te stroomlijnen en klantervaringen te verbeteren.
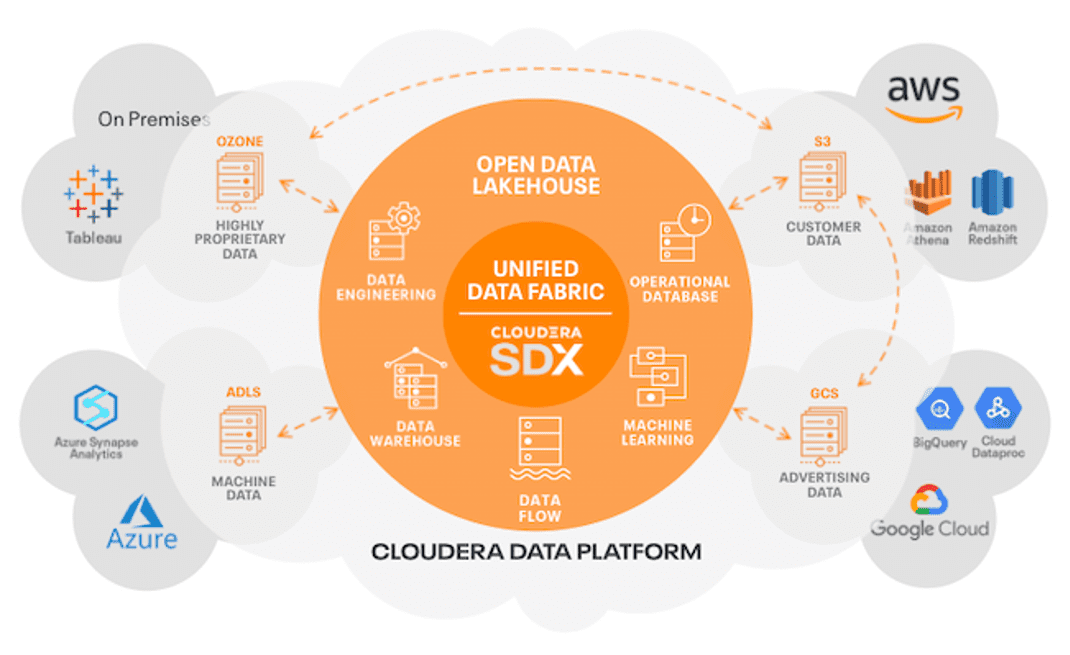
Pinecone’s vectordatabase is een belangrijke basis voor generatieve AI. Pinecone is geoptimaliseerd om AI-representaties van data op te slaan (vectorinbedding) en deze daarna op semantische gelijkenis te doorzoeken, iets waar traditionele databases inefficiënt in zijn. Deze functionaliteit is noodzakelijk voor het toevoegen van context aan query’s tegen toepassingen die misbruik maken van Large Language Models (LLM’s). Die context vermindert het aantal foutieve resultaten, aangeduid als ‘hallucinaties’, waardoor zoek- en generatieve AI-applicaties antwoorden kunnen leveren die accuraat en relevant zijn.
Door de samenwerking van Cloudera met Pinecone kunnen organisaties gemakkelijker zeer schaalbare, realtime, AI-aangedreven applicaties op Cloudera bouwen en implementeren. Dit omvat de release van een nieuw Applied ML Prototype (AMP) waarmee ontwikkelaars sneller nieuwe kennisbanken kunnen creëren en uitbreiden op basis van data op hun eigen website, evenals vooraf gebouwde connectoren waarmee klanten sneller invoerpijplijnen in AI-applicaties kunnen opzetten. In de nieuwe AMP gebruikt de vectordatabase van Pinecone deze kennisbanken om context in de reacties van chatbots te brengen, waardoor nuttige resultaten worden gegarandeerd.
Klanten kunnen dezelfde architectuur benutten om supportchatbots of interne supportzoeksystemen op te zetten, of te verbeteren. Deze dragen bij aan het verder verlagen van de operationele kosten omdat er minder menselijke inspanningen nodig zijn voor de afhandeling van vragen, terwijl de klantervaring te verbeteren is met snellere responsetijden.
Ondersteuning NVIDIA AI-technologieën
Cloudera breidt ook de ondersteuning voor belangrijke NVIDIA AI-technologieën in publieke en private clouds uit, om klanten in staat te stellen op een efficiënte wijze de beste AI-applicaties te bouwen en te implementeren. Deze nieuwe fase in de samenwerking tussen beide bedrijven voegt multigenerationele GPU-mogelijkheden toe voor data-engineering, ML en AI in publieke en private clouds.
Cloudera Machine Learning (CML) is een service van het Cloudera Data Platform die organisaties in staat stelt eigen AI-applicaties te creëren. Ze kunnen het potentieel van open-source Large Language Models (LLM’s) ontsluiten door eigen data-assets te gebruiken voor veilige en contextueel accurate reacties. Die CML-service ondersteunt nu de geavanceerde NVIDIA H100 GPU, in openbare clouds en in datacenters.
NVIDIA’s volgende generatie GPU versterkt het dataplatform van Cloudera, waardoor snellere inzichten en efficiëntere generatieve AI-workloads mogelijk zijn. Dit resulteert in de mogelijkheid om modellen op grotere datasets te verfijnen en grotere modellen in productie te hosten. De beveiliging en governance van CML op bedrijfsniveau betekent dat bedrijven de kracht van NVIDIA GPU’s kunnen benutten zonder concessies te doen aan de gegevensbeveiliging.
Cloudera Data Engineering (CDE) is een dataservice waarmee gebruikers betrouwbare en productieklare datapijplijnen kunnen bouwen van sensoren, sociale media, marketing, betaling, HR, ERP, CRM of andere systemen op het open data lakehouse. Met ingebouwde beveiliging en governance en georkestreerd met Apache Airflow, een open source-project voor het bouwen van pijplijnen in machine learning.
Via de NVIDIA Spark RAPIDS-integratie in CDE is het extraheren, transformeren en laden van workloads (ETL) te versnellen zonder dat refactoring nodig is. Bestaande Spark ETL-applicaties zijn 7x te versnellen en tot 16x bij specifieke queries, vergeleken met standaard CPU’s (op basis van interne benchmarks). Hierdoor kunnen klanten van NVIDIA profiteren van GPU’s in upstream dataverwerkingspijplijnen, waardoor het gebruik van die GPU’s toeneemt en een hoger investeringsrendement wordt bereikt.
AWS Bedrock
Cloudera heeft onlangs ook een Strategic Collaboration Agreement (SCA) ondertekend met Amazon Web Services, Inc. (AWS). Deze SCA versterkt de relatie van Cloudera met AWS en benadrukt de gezamenlijke inzet om cloud-native databeheer en data-analyse op AWS te versnellen en op te schalen. Op basis van genoemde overeenkomst gaat Cloudera AWS-services inzetten om klanten de kans te bieden continu te innoveren en hun kosten te verlagen met Cloudera open data lakehouse op AWS, voor generatieve AI. Een voorbeeld daarvan is de volledig beheerde serverloze service Amazon Bedrock.
Cloudera benut de kracht van Amazon Bedrock om klanten de mogelijkheid te bieden snel en eenvoudig generatieve AI-applicaties te bouwen met nieuwe Cloudera-functies. Met de algemene beschikbaarheid van Amazon Bedrock brengt Cloudera zijn nieuwste Applied ML-prototype (AMP) uit. Deze is gebouwd met Cloudera Machine Learning: CML Text Summarization AMP en Amazon Bedrock. Met AMP kunnen klanten basismodellen gebruiken die beschikbaar zijn in Amazon Bedrock voor tekstsamenvatting van data die in Cloudera Public Cloud op AWS en in Cloudera Private Cloud on-premise worden beheerd.
