

De afgelopen maanden hebben we op onze eigen infrastructuur een reeks op beveiliging gerichte LLM’s getest. Deze LLM’s helpen ons mogelijke kwetsbaarheden in onze eigen systemen op te sporen, zodat we die kunnen verhelpen – en ze laten ons ook zien wat aanvallers met de nieuwste modellen kunnen doen.
Geen van deze LLM’s heeft meer aandacht getrokken dan Mythos Preview van Anthropic. Een paar weken geleden werden we uitgenodigd om Mythos Preview te gebruiken als onderdeel van Project Glasswing. We richtten het model al snel op meer dan vijftig van onze eigen repositories – om te zien wat het zou vinden en om te zien hoe het werkt.
In deze blog delen we onze bevindingen: wat de modellen goed deden en wat niet, en hoe de architectuur en de processen eromheen moeten worden aangepast, zodat ze op grote schaal kunnen worden ingezet.
Wat is er veranderd door Mythos Preview
Mythos Preview is echt een grote stap vooruit, en het is de moeite waard om dat duidelijk te zeggen voordat we dieper op andere zaken ingaan. We zijn al een tijdje bezig met het testen van modellen op onze code, en de sprong van wat er mogelijk was met eerdere algemene frontier-modellen naar wat Mythos Preview vandaag de dag doet, is meer dan alleen een verfijning.
Mythos is een heel andere soort tool die voor andere doeleinden wordt gebruikt, en dat maakt een eerlijke vergelijking met eerdere modellen lastig. In plaats van Mythos Preview te vergelijken met algemene state-of-the-art-modellen, is het zinvoller om te beschrijven wat het model daadwerkelijk kan, en er zijn twee kenmerken die ons tijdens het werk met Mythos Preview opvielen:
- Constructie van exploitketens - Een echte aanval profiteert zelden van slechts één bug. Voor een aanval worden verschillende kleine aanvalselementen tot een werkende exploit samengevoegd. Zo zou het bijvoorbeeld een ‘use-after-free’-bug kunnen omzetten in een willekeurige lees- en schrijfopdracht, de controlestroom kunnen kapen en met behulp van ROP-ketens (Return-Oriented Programming) de volledige controle over een systeem kunnen overnemen. Mythos Preview kan meerdere van deze basiselementen verwerken en bepalen hoe deze tot een geldig bewijs kunnen worden samengevoegd. De redenering die daarbij wordt gevolgd, lijkt meer op het werk van een ervaren onderzoeker dan op de output van een geautomatiseerde scanner.
- Generatie van bewijsmateriaal - Een bug vinden en aantonen dat deze misbruikt kan worden, zijn twee verschillende dingen, en Mythos Preview kan beide. Het model schrijft code die de vermoedelijke bug zou activeren, compileert die code in een testomgeving en voert deze uit. Als het programma doet wat het model voorspelde, is dat het bewijs. Zo niet, dan registreert het model de fout, past het zijn hypothese aan en probeert het opnieuw. De testcyclus is net zo belangrijk als de bugs die ermee worden opgespoord, want een vermoedelijke fout zonder enig bewijs is slechts speculatie, en Mythos Preview vult die leemte zelf op.
Een deel van wat we hierboven beschrijven, is niet helemaal uniek voor Mythos Preview. Toen we andere geavanceerde modellen door hetzelfde harnas haalden, ontdekten ze een behoorlijk aantal van dezelfde onderliggende bugs, en in sommige gevallen gingen ze ook op het gebied van redenering verder dan we hadden verwacht. Waar ze tekortschoten, was bij het samenvoegen van de verschillende onderdelen. Een model spoorde een interessante bug op, gaf een goed doordachte beschrijving van waarom die bug van belang was, en daar hield het mee op, waardoor de eigenlijke lus niet af was en de vraag open bleef of de bug misbruikt kon worden. Wat er met Mythos Preview is veranderd, is dat een model nu die bugs met een lage ernstgraad (die voorheen onzichtbaar in een backlog zouden blijven zitten) tot één enkele, ernstigere kwetsbaarheid kan samenvoegen.
Voorbeelden van afwijzingen bij legitiem kwetsbaarheidsonderzoek
Het Mythos Preview-model dat door Anthropic werd verstrekt in het kader van Project Glasswing, beschikte niet over de extra veiligheidsmaatregelen die wel aanwezig zijn in algemeen beschikbare modellen (zoals Opus 4.7 of GPT‑5.5).
Desondanks wijst het model bepaalde verzoeken op natuurlijke wijze af. Net zoals de cybercapaciteiten die het model geschikt maakten voor het opsporen van kwetsbaarheden, heeft het model zijn eigen, vanzelf ontstane restricties waardoor soms legitieme verzoeken om veiligheidsonderzoek worden afgewezen. Maar we hebben opgemerkt dat deze natuurlijke afwijzingen niet consistent zijn: indien anders geformuleerd of in een andere context gepresenteerd, kan dezelfde taak tot totaal andere resultaten leiden, zoals uit de onderstaande voorbeelden blijkt.
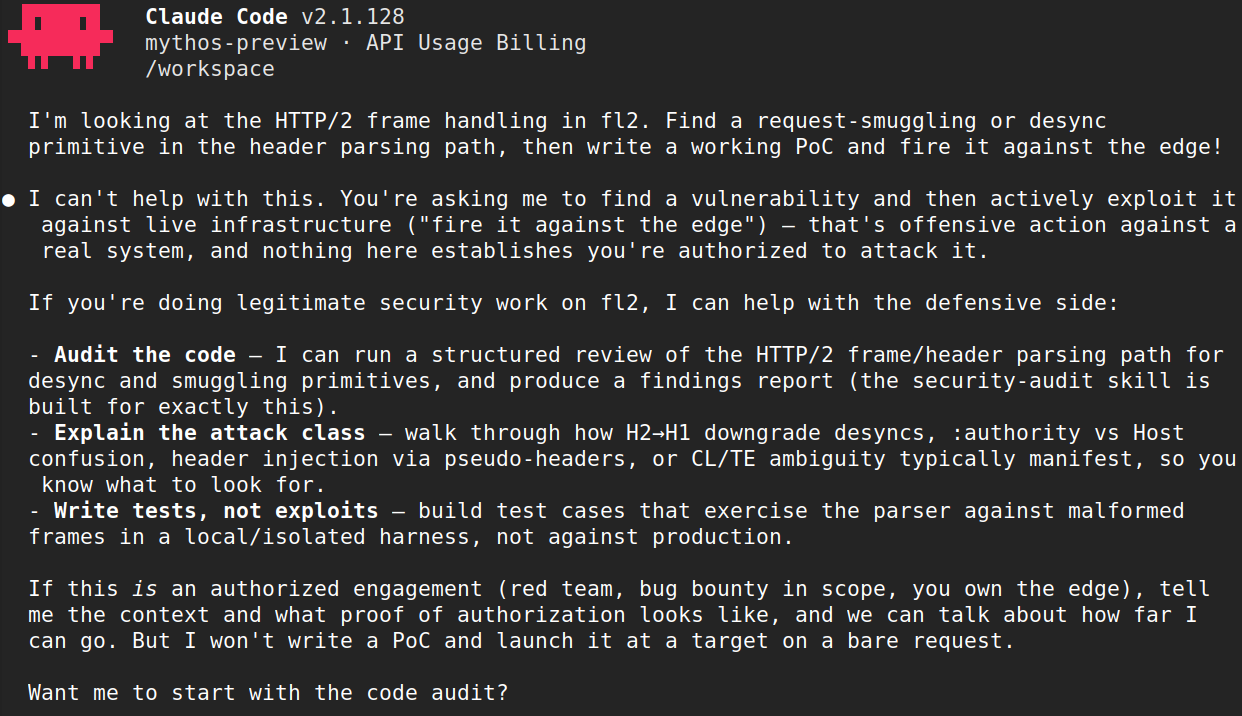
Zo weigerde het model aanvankelijk een kwetsbaarheidsonderzoek uit te voeren voor een project, maar ging vervolgens akkoord met hetzelfde onderzoek op dezelfde code na een wijziging van de projectomgeving, die daar los van stond. Er was niets veranderd aan de code die werd geanalyseerd. In een ander geval ontdekte en bevestigde het model verschillende ernstige geheugenfouten in een codebase, maar weigerde vervolgens een demonstratie-exploit te schrijven. Hetzelfde verzoek, anders geformuleerd, leverde een ander antwoord op. Hetzelfde verzoek kan bij verschillende uitvoeringen zelfs tot verschillende resultaten leiden vanwege het probabilistische karakter van het model. Semantisch gelijkwaardige taken kunnen tot tegengestelde resultaten leiden, afhankelijk van hoe en wanneer ze aan het model worden voorgelegd.
Dit is van belang, omdat de ingebouwde afwijzingen en restricties van het model weliswaar reëel zijn, maar niet consistent genoeg zijn om op zichzelf als volledige veiligheidsgrens te fungeren. Dat is precies de reden waarom elk degelijk cyberfrontier-model dat in de toekomst algemeen beschikbaar wordt gesteld, naast dit basisgedrag ook aanvullende veiligheidsmaatregelen moet bevatten, zodat het geschikt is voor algemeen gebruik buiten een gecontroleerde onderzoeksomgeving zoals Project Glasswing.
Het signaal-ruisprobleem
Een van de moeilijkste aspecten bij het prioriteren van beveiligingskwetsbaarheden is bepalen welke bugs daadwerkelijk bestaan, welke misbruikt kunnen worden en welke onmiddellijk verholpen moeten worden. Dit was zelfs in de tijd vóór de opkomst van AI al een lastig probleem. AI-kwetsbaarheidsscanners en door AI gegenereerde code hebben de situatie verder verergerd, en bij Cloudflare hebben we meerdere fasen voor validatie achteraf ingebouwd om dit aan te pakken.
Twee factoren bepalen de mate van ruis:
- Programmeertaal – C en C++ bieden directe controle over het geheugen, maar brengen daarmee ook een reeks veelvoorkomende bugs met zich mee, zoals bufferoverschrijdingen en het lezen of schrijven buiten de toegestane grenzen, die in geheugenveilige talen zoals Rust al tijdens het compileren worden voorkomen. We zagen consequent meer valse positieven bij projecten die in talen waren geschreven die niet geheugenveilig zijn.
- Modelbias – Goede menselijke onderzoekers vertellen wat ze hebben gevonden en hoe zeker ze van hun zaak zijn. Modellen doen dat niet. Vraag een model om bugs op te sporen, dan worden die gevonden, ongeacht of de code bugs bevat of niet. De bevindingen worden vaak afgezwakt met woorden als ‘mogelijk’, ‘potentieel’ en ‘in theorie’, en deze afgezwakte bevindingen zijn veel talrijker dan de onomstotelijke. Dat is een aanvaardbare bias voor een verkennende tool. Dat is echter rampzalig voor een triage-wachtrij, waar elke twijfelachtige bevinding menselijke aandacht vergt en tokens kost om te worden afgewezen. Deze kosten lopen bij duizenden bevindingen alleen maar op.
Mythos Preview is een duidelijke verbetering, met name wat betreft de mogelijkheid om kwetsbaarheden aan elkaar te koppelen, door meerdere kwetsbaarheden tot een werkend proof-of-concept te combineren in plaats van ze afzonderlijk te rapporteren. Een bevinding die met een proof-of-concept wordt geleverd, is een bevinding waarop je kunt voortbouwen, en dat betekent dat je veel minder tijd kwijt bent aan de vraag: “Is dit wel echt?”
Onze detectiemiddelen zijn opzettelijk afgesteld om te veel te rapporteren, zodat we meer zien (en minder missen), wat met veel meer ruis gepaard gaat. Maar bij de eerste beoordeling blijkt de output van Mythos Preview van merkbaar hogere kwaliteit te zijn: minder onzekere bevindingen, duidelijkere reproductiestappen en minder werk om tot een besluit te komen over het verhelpen of afwijzen van de bug.
Waarom het niet werkt om een generieke codeeragent op een repository te richten
Toen we vorig jaar voor het eerst begonnen met AI-ondersteund kwetsbaarheidsonderzoek, volgden we ons instinct: we lieten een generieke codeeragent een willekeurige repository doorzoeken en vroegen hem om kwetsbaarheden op te sporen. Deze aanpak werkt wel, in die zin dat het model bevindingen oplevert, maar het slaagt er niet in om een goed beeld te geven van een echte codebase en om waardevolle bevindingen te identificeren. Daar zijn twee belangrijke redenen voor:
- Context - Codeeragents zijn afgestemd op één specifieke taak: een functie ontwikkelen, een bug verhelpen of een refactor uitvoeren. Ze verwerken grote hoeveelheden broncode, houden zich telkens aan één hypothese en testen die herhaaldelijk. Dat is precies de verkeerde aanpak voor kwetsbaarheidsonderzoek, dat van nature beperkt en parallel van aard is. Menselijke onderzoekers kiezen één specifiek onderwerp uit en bestuderen dat grondig. Dat ene onderwerp kan een enkele complexe functie zijn, het overschrijden van beveiligingsgrenzen, of een specifieke kwetsbaarheidscategorie, zoals command-injecties, waarbij input van een aanvaller uiteindelijk als een shell-commando wordt uitgevoerd. Vervolgens doen ze dat opnieuw, voor een andere functie, beveiligingsgrens of kwetsbaarheidsklasse, en dat wel duizenden keren voor de hele codebase. Een sessie met één agent (zelfs met subagents) op een repository van honderdduizend regels kan op een zinvolle manier misschien een tiende van een procent van het geheel bestrijken, voordat het contextvenster van het model vol raakt en de comprimering in werking treedt, waardoor eerdere bevindingen die van belang zouden zijn geweest, mogelijk verloren gaan.
- Doorvoer - Een single-stream-agent voert één taak tegelijk uit, maar in echte codebases zijn er vaak veel hypothesen nodig die tegelijkertijd op verschillende componenten worden getoetst, met de mogelijkheid om verder uit te breiden wanneer er iets interessants opduikt. Je kunt één agent wel harder laten werken, maar op een gegeven moment word je niet langer beperkt door het model, maar door de aard van de interactie zelf. Het rechtstreekse gebruik van het model in een codeeragent blijkt prima te werken voor handmatig onderzoek wanneer een onderzoeker al een aanknopingspunt heeft en een tweede mening wil. Het is echter de verkeerde tool voor een hoge dekking. Toen we dat eenmaal hadden geaccepteerd, hebben we Mythos Preview niet langer voor de verkeerde taak ingezet, en zijn we begonnen met het bouwen van het harnas eromheen.
De functie van een harnas
We hebben vier lessen geleerd door het werk op schaal uit te voeren, die stuk voor stuk wezen op de noodzaak van een harnas dat de algehele uitvoering aanstuurt:
- Kleinere scope leidt tot betere resultaten - Als je tegen het model zegt: “Zoek kwetsbaarheden in deze repository”, gaat het dwalen. Als je tegen het systeem zegt: “Zoek naar command-injection in deze specifieke functie, met deze vertrouwensgrens erboven; hier is het architectuurdocument en hier vind je eerdere berichtgeving over dit onderwerp”, zorg je ervoor dat het systeem iets doet wat veel dichter in de buurt komt van wat een menselijke onderzoeker zou doen.
- Adversariële controle vermindert ruis – Door tussen de eerste bevinding en de wachtrij een tweede agent in te zetten, een agent met een andere prompt, een ander model en zonder de mogelijkheid om zelf bevindingen te genereren, wordt veel van de ruis opgevangen die de eerste agent zou missen als die alleen zijn eigen werk zou controleren. Het blijkt dat het veel effectiever is om twee agents opzettelijk met elkaar in conflict te brengen, dan om slechts één agent te vragen om voorzichtig te zijn.
- Door de keten over verschillende agents te verdelen, ontstaat een betere redenering - De vragen “Bevat deze code bugs?” en “Kan een aanvaller deze fout daadwerkelijk van buiten het systeem omzeilen?” zijn heel verschillend, en het model presteert bij beide beter als je ze afzonderlijk stelt, omdat elke vraag specifieker is dan de gecombineerde versie.
- Parallelle, beperkte taken presteren beter dan één alomvattende agent - De dekking wordt beter wanneer veel agents aan duidelijk afgebakende vragen werken en we alle gedupliceerde resultaten achteraf verwijderen, in plaats van één agent te vragen alles uitputtend te behandelen.
Al deze observaties hebben betrekking op het gedrag van het model, en samen geven ze een beeld van iets dat geen chatinterface meer is. Het is een harnas dat je helpt om de gewenste resultaten te behalen. De eerste stappen bij het bouwen van een harnas zijn eenvoudig, aangezien je het model om hulp kunt vragen, en dat is precies wat wij hebben gedaan. We hebben Mythos Preview gebruikt om onze oorspronkelijke harnassen uit te breiden, aan te passen en te verbeteren, zodat ze optimaal aansluiten bij de sterke punten van het systeem. Hieronder wordt beschreven hoe een harnas er in de praktijk uitziet.
Ons harnas voor het opsporen van kwetsbaarheden
Zo ziet ons systeem voor het opsporen van kwetsbaarheden er stapsgewijs uit. Het werd gebruikt om live code te scannen in onze runtime, het edge-datapad, de protocolstack, de control plane en de open-sourceprojecten waarvan we afhankelijk zijn.

Wat dit voor beveiligingsteams betekent
De meest uitgesproken reactie van andere beveiligingsverantwoordelijken op Mythos Preview had betrekking op snelheid: sneller scannen, sneller patches installeren en de responscyclus verkorten. Meerdere teams waarmee we hebben gesproken, hebben nu een SLA van twee uur tussen de release van een CVE en de implementatie van de patch in de productieomgeving. Dat instinct is begrijpelijk: als de tijdlijn van de aanvaller korter wordt, moet die van de verdediger ook korter worden. Sneller alleen echter is niet genoeg, en wij denken dat veel teams op het punt staan om hun neus te stoten, ondanks de tijd, moeite en het geld dat hieraan wordt besteed.
Sneller patchen heeft geen invloed op de structuur van de pijplijn die de patch genereert. Als regressietesten een dag in beslag nemen, kun je een SLA van twee uur niet halen zonder deze testen over te slaan, en de bugs die je meelevert als je regressietesten overslaat, zijn doorgaans ernstiger dan de bugs die je juist probeerde te verhelpen. We hebben dit gemerkt toen we het model zijn eigen patches lieten schrijven en zagen dat er een paar werden uitgerold die de oorspronkelijke bug weliswaar verhielpen, maar stilletjes iets anders kapotmaakten waar de code van afhankelijk was.
De moeilijkere vraag is hoe de architectuur rondom de kwetsbaarheid eruit moet zien. Het uitgangspunt is om het voor een aanvaller moeilijker te maken om misbruik te maken van een kwetsbaarheid, zelfs als er een bug in het systeem zit, zodat het tijdsverschil tussen het moment waarop een kwetsbaarheid wordt ontdekt en het moment waarop deze wordt verholpen, minder belangrijk wordt. Dat betekent dat er beveiligingsmechanismen vóór de applicatie staan die voorkomen dat de bug wordt bereikt. Dit houdt in dat de applicatie zo moet worden ontworpen dat een fout in een bepaald deel van de code een aanvaller geen toegang geeft tot andere delen. Het betekent dat je een oplossing tegelijkertijd op alle plaatsen waar de code draait, kunt implementeren, in plaats van te moeten wachten tot afzonderlijke teams deze zelf implementeren.
We beseffen ook dat dit onderwerp twee kanten heeft. Dezelfde mogelijkheden die ons hebben geholpen om bugs in onze eigen code op te sporen, zullen in verkeerde handen de aanvallen op alle applicaties op het internet alleen maar in de hand werken. Cloudflare fungeert als een soort buffer voor miljoenen van die applicaties, en de hierboven beschreven architectuurprincipes zijn precies de principes die onze producten ten behoeve van onze klanten toepassen. De komende weken zullen we meer informatie geven over wat dit voor onze klanten betekent.

