
Cloudflare maakt bekend dat ontwikkelaars complete AI-applicaties kunnen bouwen op haar wereldwijde netwerk. Het ontwikkelaarsplatform van Cloudflare biedt ontwikkelaars de mogelijkheid om op een snelle en betaalbare wijze volledige AI-applicaties te bouwen, zonder de daarvoor benodigde infrastructuur te hoeven beheren. Alle bedrijven, van startups tot grote ondernemingen, proberen momenteel het dienstenaanbod aan te vullen met kunstmatige intelligentie. Daarom biedt het platform van Cloudflare ontwikkelaars nu de capaciteit om snel een direct bruikbare toepassing te lanceren met ingebouwde beveiliging, compliance en snelheid.
Snel meerwaarde leveren
Businessmanagers, van grote bedrijven die hun dienstenaanbod willen uitbreiden met AI, tot AI-startups met een missie om de volgende generatie applicaties te bouwen, willen op grote schaal AI-toepassingen kunnen leveren. Organisaties proberen momenteel snel te handelen om meerwaarde te realiseren. Ze worden echter geconfronteerd met uitdagingen, zoals snel oplopende en ondoorzichtige kosten om AI toe te passen en ervoor te zorgen dat informatie van klanten privé blijft en voldoet aan de regelgeving. Ontwikkelaars worden geconfronteerd met veel nieuwe leveranciers, waardoor ze nieuwe tools snel moeten begrijpen en veel complexe, ongelijksoortige applicaties met elkaar moeten verbinden. C‑level managers zijn op zoek naar kostenoptimalisatie, te midden van dure technologie, tools en personeel.
AI-inferentie dichtbij gebruikers
“Cloudflare heeft alle benodigde infrastructuur voor ontwikkelaars die schaalbare AI-toepassingen willen bouwen en kan daarmee dicht bij de gebruikers AI-inferentie aanbieden. Wij blijven investeren, zodat we elke ontwikkelaar krachtige, betaalbare tools kunnen bieden voor het bouwen van de toekomst”, zegt Matthew Prince, CEO en medeoprichter van Cloudflare. “Workers AI biedt ontwikkelaars alle benodigde mogelijkheden om in enkele dagen op een efficiënte en betaalbare wijze, kant en klare AI-ervaringen te bouwen, in plaats van de weken of zelfs maanden die het nu vaak kost voor een volledig team.”
“Organisaties kiezen vaker voor kunstmatige intelligentie bij het maximaliseren van hun operationele efficiëntie”, zei Stephen O’Grady, Principal Analyst bij RedMonk. “Maar het is cruciaal om ontwikkelaars een hoogwaardige ervaring voor hun AI-gebruik te bieden, met abstracties voor het vereenvoudigen van de interfaces en controles voor de kostenbeheersing. Dat is exact waarvoor Cloudflare het Workers-platform heeft geoptimaliseerd.”
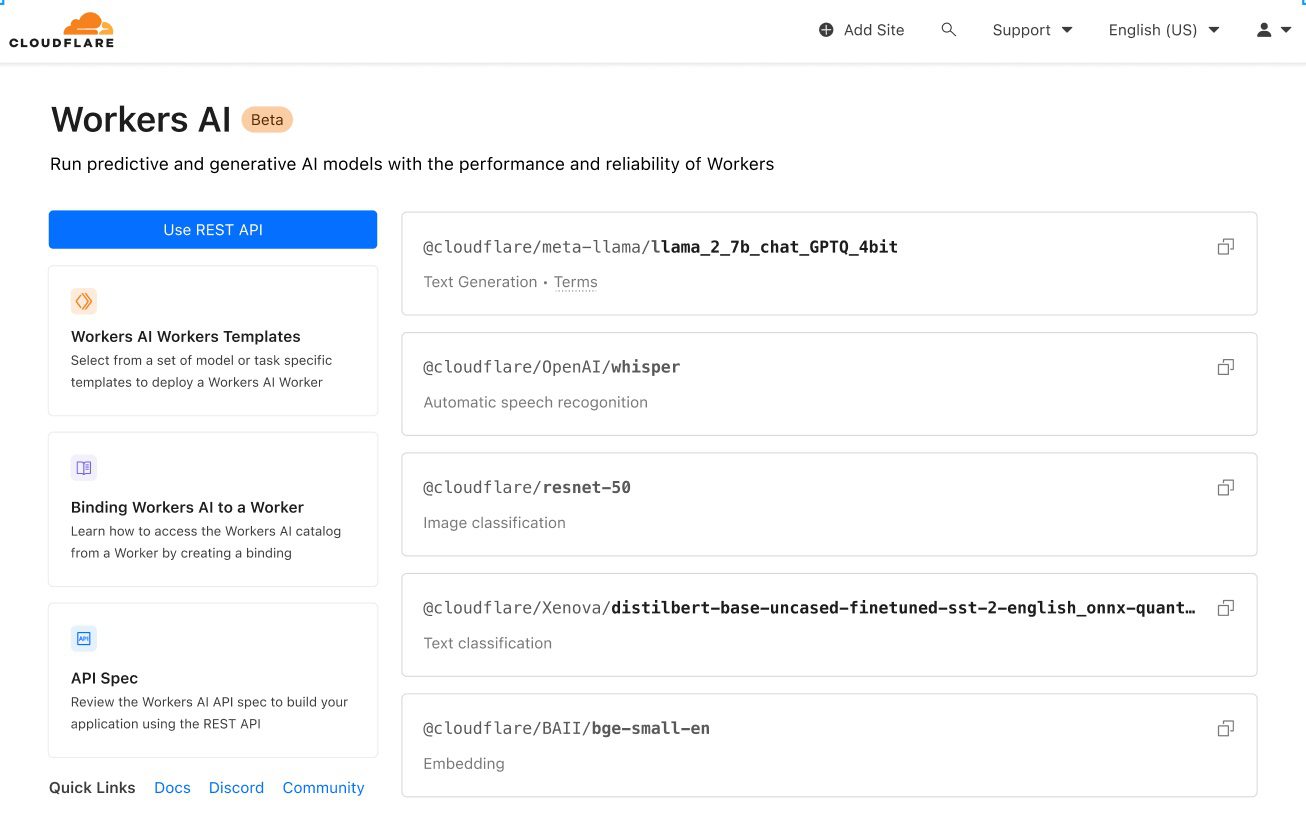
Workers AI: de eerste serverloze en schaalbare AI
Workers AI biedt ontwikkelaars een eenvoudige en betaalbare manier voor het draaien van AI-modellen op Cloudflare’s wereldwijde netwerk. Cloudflare biedt nu, mede via samenwerkingsverbanden, toegang tot GPU’s die draaien op haar gigantische wereldwijde netwerk. Dit maakt het mogelijk om AI-inferentie dicht bij gebruikers uit te voeren, zodat zij minder lang hoeven te wachten. Als dat wordt gecombineerd met de Data Localization Suite voor het controleren van de locaties waar data wordt geïnspecteerd, kan Workers AI klanten ook helpen bij het anticiperen op mogelijke compliancy eisen, als overheden beleid voor het AI-gebruik gaan invoeren. Privacy staat altijd voorop bij de aanpak van Cloudflare voor het ontwikkelen van applicaties. Dit kan organisaties helpen bij het houden van hun beloftes aan klanten om te waarborgen dat data voor inferentie niet wordt gebruikt voor het trainen van LLM’s. Cloudflare ondersteunt nu een modelcatalogus waarmee ontwikkelaars snel aan de slag kunnen, voor toepassingen als LLM, spraak-naar-tekst, afbeeldingclassificatie, sentimentanalyse en meer.
Vectorize: een vectordatabase die AI-werkstromen versnelt
De nieuwe vectordatabase van Cloudflare, Vectorize, biedt ontwikkelaars mogelijkheden om complete AI-toepassingen op Cloudflare’s platform te bouwen. Vanaf het genereren van inbeddingen voor de ingebouwde modellen in Workers AI en het indexeren hiervan in Vectorize, tot queries en het opslaan van de brondata in R2. Workers AI en Vectorize zorgen ervoor dat ontwikkelaars zich niet meer bezig hoeven te houden met het aan elkaar plakken van verschillende onderdelen om AI en ML te kunnen toevoegen aan hun apps. Dit gebeurt allemaal op hetzelfde platform.
Vectorize profiteert ook van het wereldwijde netwerk van Cloudflare, zodat vectorverzoeken dichter bij gebruikers plaatsvinden, waardoor de latentie en de algehele inferentietijd lager worden. Het is ook geïntegreerd in het AI-ecosysteem in bredere zin, zodat ontwikkelaars inbeddingen aangemaakt met OpenAI en Cohere kunnen opslaan. Dit biedt teams de mogelijkheid om bestaande inbeddingen te gebruiken en nog steeds te profiteren van Vectorize voor het schalen van AI-apps naar de productie.
AI Gateway: observeerbaarheid en schaalbaarheid voor AI
Cloudflare introduceert ook nog AI Gateway, voor betrouwbaardere, observeerbare en schaalbare AI-applicaties. Uit de laatste voorspellingen van IDC blijkt dat de uitgaven aan AI dit jaar waarschijnlijk groeien tot $ 154 miljard en in 2026 tot zo’n $ 300 miljard. Ontwikkelaars en C‑level managers weten echter amper hoeveel geld er wordt besteed aan de AI-infrastructuur, of hoeveel queries er vanaf waar worden uitgevoerd.
Ontwikkelaars moeten zich volledig kunnen focussen op hetgeen ze proberen te bouwen en niet op de infrastructuur, kosten, observeerbaarheid of schaalbaarheid die daarbij horen. Daarom biedt AI Gateway ontwikkelaars de benodigde functionaliteit voor het verkrijgen van inzichten in al het AI-verkeer, zoals het aantal aanvragen, het aantal gebruikers, de gebruikskosten van de app en tijdsduur van verzoeken.
Tenslotte kunnen gebruikers de kosten beheersen met caching en snelheidsbeperking. Caching biedt klanten de mogelijkheid om antwoorden te cachen voor herhaalde vragen, zodat er niet telkens meerdere aanvragen naar dure API’s hoeven te worden gestuurd. Snelheidsbeperking helpt bij het tegenhouden van kwaadaardige partijen en zwaar verkeer voor het managen van de groei en kosten, waardoor gebruikers meer controle krijgen over de wijze waarop ze hun applicaties schalen.
